過去我們談了關於 Synchronous Feature (Realtime Feature) 和 Asynchronous Feature (Batch Feature) 的不一緻性,換句話說,也就是 Training Feature 和 Serving Feature 可能有著不同的計算邏輯,而這樣的誤差就會導致 Inference 本身多了一個不可控性,除了這點外在整個 Serving 過程中還有以下幾個問題
當然可以把所有 Event Log 都存下來,並重現發生過的 Event 來重新計算 PIpeline,但這樣計算速度很慢,所以這裡要提出一個 Feature Store 的 Solution 來解決以上的問題
Feature Store 是 Storage (滿常看到用 TiDB 實作),用於存儲、查詢、和管理機器學習特徵,換句話來說 Feature Store 做了以下幾件事情
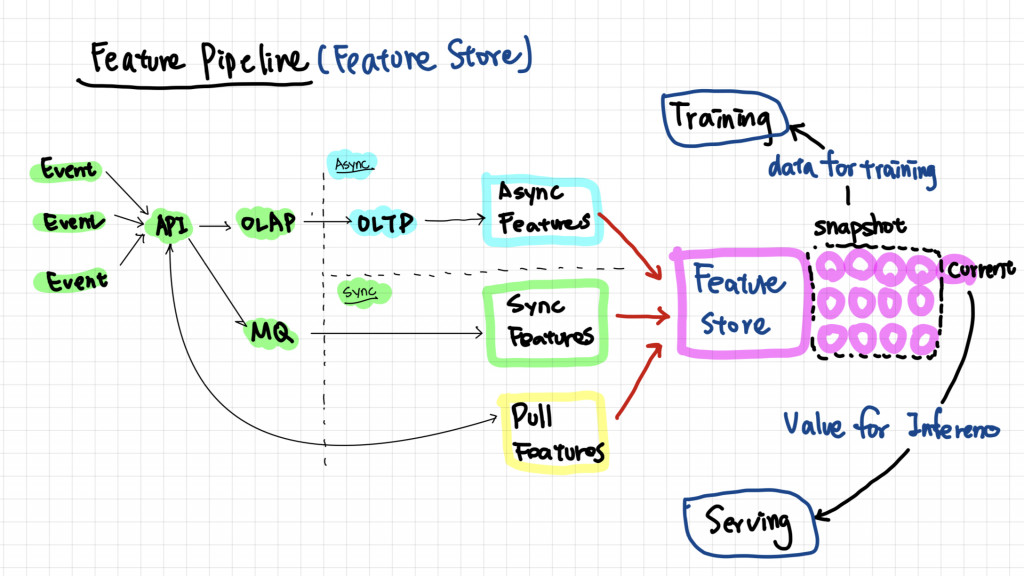
透過以上的機制 Feature Store 可以做到幾點:
然而我們可以看到上述的 Feature Store Solution 有幾個問題
重點不在於是不是要導入 Feature Store 到 MLOps 系統中,而是 Feature Store 為了解決的幾個問題是否帶給你們團隊困擾,當 Feature Store 的系統被建立且實作一段時間後,可以帶來的效益是提升模型上線速度 (因為特徵可重複使用),並且更好的做後續的 Monitoring 機制
另外除了一開始提到的備份整個 Message Queue 來重現外,也很常見到使用 Spark RDD 特性來解決特徵醫治性的問題,總而言之,每個團隊會有最適合自己的方法,在 Serving 的部分我們就先停在這
Inference Serving 在 Structure Data 的 Binary Classification 中相對單純,不外乎是將模型包裝成一個 zip 並放到 Function as a service 的服務或是將 Model 包裝成一個 FastAPI endpoint 放到 Platform as a service 的服務中,或是透過 Kubernetes 來管理,由於這部分我認為這集比較多 DevOps 最佳實踐所以就不在這邊展開


 iThome鐵人賽
iThome鐵人賽